网易新闻全链路状态追踪解决方案
网易新闻从2016年开始接入网络性能监控平台,便于提供网络监控和预警的功能。然而由于客户端对接的服务后台有很多,比如跟帖后台,广告后台,统计后台等等,再加上有不同的 CDN 服务提供商和内外部的 APM(性能监控)服务商;对接后台的增多就导致了我们在排查网络问题的时候难度很大,特别是针对一些非地域性问题,某一个用户单独出现的网络异常问题排查成本非常大。举一个比较具体的实例问题: 针对反馈平台用户反馈的网络图片无法显示问题,我们需要排查用户请求的状况,找出出错的环节。
针对上述问题我们一般的做法是: 拉取用户日志,查看网络请求是否正常发送,服务端正常返回。如果发送请求是正常的,我们需要排查服务端日志,是否有接收到这个请求。服务端如果没有接收到此请求,我们就需要调取 CDN 服务商的日志,查看 CDN 服务器是否接收到了此请求。在这样的一个排查过程中我们传统意义上的依据只有用户 ip 和请求的大概时间。然而通过 ip 和时间不能精确的从服务端日志找到这个请求,于是排查就陷入了僵局。
为了解决上述状况,我们制定了一套请求唯一标识的方案。何为请求唯一标识? 唯一标识就是指,客户端发送每一个请求之前,给此请求生成唯一 traceId,此 id 能够唯一标识一个请求。在 CDN 服务和我们后台服务以及我们的 APM 性能监控平台中,我们统一在日志中记录请求和其唯一 traceId。这样一来,我们只要知道了这个请求的唯一 traceId, 无论在哪个服务节点,我们都可以在日志中获取精准的该请求的详细日志信息。比如: APM 性能监控平台上报某用户某个请求是失败的,此时我们只需要拿此请求的 traceId 从后台日志和 CND 日志中查看该请求的信息,这样就清晰的定位了问题发生的环节,这样找到了出现异常的环节,剩下的事情就是具体的排查和解决了。具体的实现方案如下图解: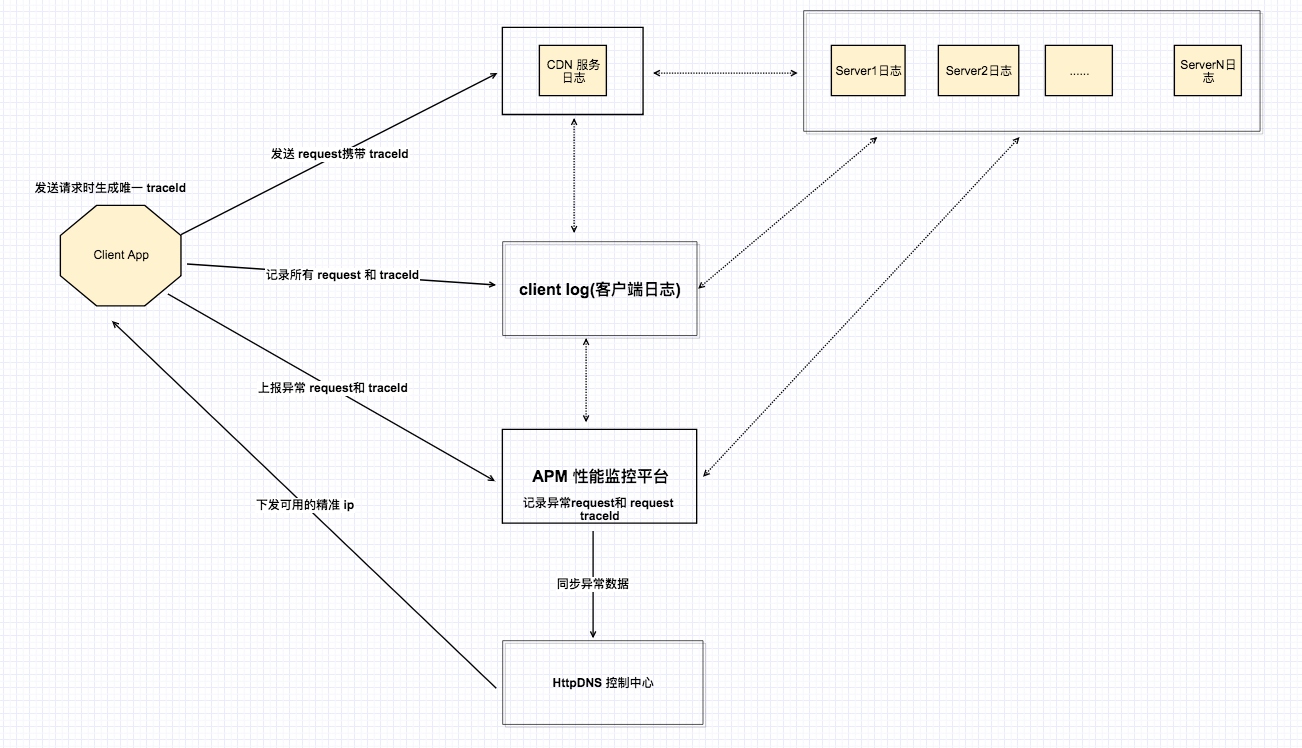
- 客户端发送请求时生成请求唯一标识 traceId, 并将此 rraceId 添加到请求 header 中;
- CND 服务日志记录请求 url 同时记录 header 中的 traceId
- 各个后台服务日志系统记录请求 url 同时记录 header 中的 traceId
- APM性能监控平台记录请求的 url 和 traceId
- 客户端日志记录请求的 url 和 traceId
这样处理完成之后,每一个请求都通过一个唯一的标识 traceId 将链路上的各个环节关联了起来。这样出现了异常或者报警的情况,我们只需要知道 traceId 就可以在各个环节排查,从而定位出来问题出现在哪里,从而有效的解决问题。
从上图还可以看到,这样一种全链路追踪解决方案不仅仅对我们在排查网络问题有很大的帮助,同时还能很大程度上解决一些网络劫持和 dns 异常的问题。如上图,我们将 apm 性能监控平台的异常数据同步给 httpDNS 控制中心,httpDNS 控制中心经过多数据的汇总和分析,将更加精确的 ip 信息下发到客户端,这样客户端就能直接通过 ip 访问服务,绕过 dns 的解析过程,大大降低了错误率和网络劫持的状况。